
Data Processing: Steps, Types and More
In part 1 of this blog post, we discussed data preprocessing in machine learning and how to do it.
That post will help you understand that preprocessing is part of the larger data processing technique; and is one of the first steps from collection of data to its analysis.
Today, you shall look at the overall aspect of data processing and why it is important in data analytics. You can do it manually, automatically, or by using electronic data processing. You are aware that information in its raw form is of no use.
The technique is a series of steps that are necessary to extract, clean, transform, and organize raw data.
The goal is to make it easier to understand and work with the data. There are many techniques, but they all share some common steps.
What is Data Processing?
Data Processing is the end-to-end process of collecting raw data and turning it into useful and actionable knowledge. It also includes data reporting and data storage. We can collect data manually or automatically.
Processing transforms big data into useful information. Once processing is complete, we must store the data.
Transform your business using Express Analytics’ machine learning solutions
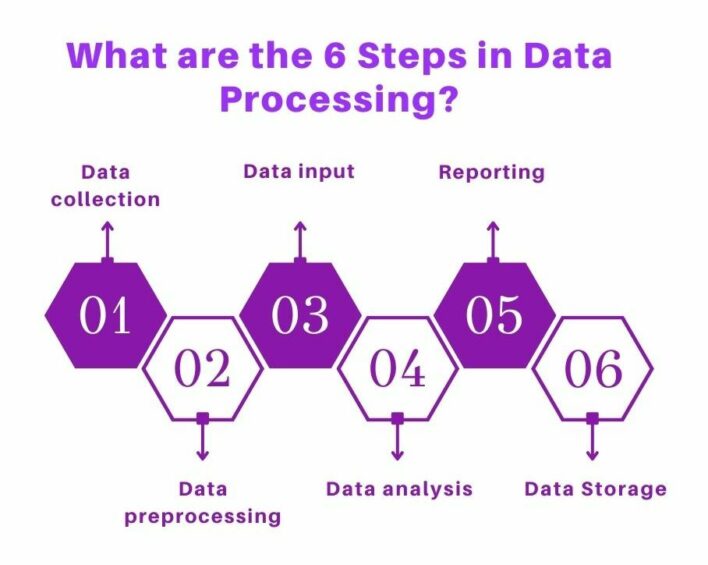
The Data Processing Steps include:
Data collection:
This is the first step, and it involves gathering data from various sources such as data lakes and data warehouses.
To ensure the collection of highest quality data and its subsequent use as information), it is essential to ensure that the data sources available are trustworthy and comprehensive.
Data preprocessing/preparation:
The second is to prepare the information for analysis. In machine learning, preprocessing involves transforming a raw dataset, so the model can use it.
This is necessary for reducing the dimension, identifying the relevant content, and increasing the performance of some machine learning models.
It involves transforming or encoding data so that a computer can quickly parse it. What’s more, predictions made by a model should be accurate and precise because the algorithm should be able to interpret the data easily.
Data Input:
During this process, we convert raw data into a machine-readable format. Next, enter the clean data into the data warehouse or CRM (such as Salesforce) and translate it into the language of the destination system.
A keyboard, scanner, or any other means of input is the first step in converting raw data into usable information.
Data analysis:
While processing is typically the first stage, the next stage of the overall data handling process is data analysis.
Data analysis is how analysts and scientists find patterns and insights in the information at hand. It is the process of using the processed data to answer questions or make decisions.
This usually involves applying statistical or machine learning techniques. It uses special algorithms and statistical calculations, and enterprises can use software suites like SAS for this.
Reporting:
This is the final step in processing, and it involves presenting the findings of the analysis to write a report.
A report is a document that summarizes the results of your data analysis and presents them in an easy-to-read format. It is useful for communicating your findings to others or yourself so that you can learn from them.
There are several types of reports that you could write. Some common ones are a report on the analysis itself, a report on the results of the data analysis, a report on the use of the data, and a report on the data analysis findings.
The purpose of such reports is usually two-fold: as preparation for publishing, but also so that they can serve as reference materials when conducting future research projects using similar methodologies or datasets.
Data storage:
This step is the storage of information in a format that is accessible and usable.
This stage allows people within an organization to access aggregate datasets when needed via existing business intelligence platforms like Tableau Software’s Tableau Online (SAAS) Business Intelligence Platform as Service (PaaS).
What is a Data Processing System and its Types?
A data processing system is one that collects, stores, and transforms the data. The term refers to a series of inputs and outputs that are the result of a combination of machines, people, and processes.
Data processing has benefited widely from computer technology, as computers have become more powerful at responding quickly. Heavy amounts of data can be gathered, with proper analysis able to be conducted rapidly.
Based on the interpreter’s relationship with the system, these inputs and outputs are decipherable as facts, information, and so on.
Processing can be either by application or service type. Application processing is a type of data processing in data analytics where we process data via an app.
This type of processing is typically useful for unstructured data and for service processing.
Accounting programs are typical examples of data processing applications because they require a large amount of input data, few computational operations, and a large amount of output.
Such organizational computer systems are studied in the field of Information Systems (IS). An example of this would be data analysis made by a bank of its daily transactions by retail customers.
Transform your business using Express Analytics’ machine learning solutions
Service processing is a type of processing in which the data is processed by a service. It is typically used for structured data.
An example is a transaction processing system (TPS), which is either a software system or a software/hardware combination that enables dividing work into indivisible units, called transactions.
Another example of service data processing is retrieving information from a collection of information systems resources that matches an information need.
It is called information retrieval in the computing world. An example would be online search.
There are several types of information retrieval, including searching for information within a document, searching for metadata that describes data, in addition to searching a database for content.
Models are: batch processing, real-time and online processing.
Batch processing means processing that is done in a batch mode. This means that the data is processed one piece at a time. It is used for large data sets that need to be processed slowly.
Real-time systems give users immediate feedback while working with their input devices like touch screen kiosks, interactive tables and so on. It gives near-instantaneous output. An example would be a bank ATM.
In real-time, the system takes the input of fast-changing data and provides output near instantaneously, and the change over time is also readily seen in such a system.
Online processing is a type that is done online. It, too, is in real-time, which means that the content is processed as it is being received.
Real-time processing is used for data that needs to be processed quickly. Streaming processing is a type of online processing that is done in a streaming mode.
An example of online processing would be any e-commerce activities.
Data Processing Tools
By now, you would have understood that data processing is critical of any business or organization. It helps to ensure that data is accurate, consistent, and timely.
There are a number of different tools available, each of which has its strengths and weaknesses.
The steps of data processing can vary depending on the tool in use but typically include data collection, data cleaning, data transformation, and analysis.
The type of data that you process will also dictate the specific steps involved. For example, financial information will require different processing than customer data.
Understanding the different data processing tools and how they work is essential for anyone who needs to work with information.
Data collection tools help you gather data from various sources. They can include databases, files, and online platforms.
Data cleaning tools clean the data before processing is complete. This includes removing incorrect information, ensuring that all data is valid, and reducing the size of the data.
Data transformation tools help you change the data format before processing is complete. This includes converting data between different formats, transforming data into a more usable form, and removing unnecessary information.
Data analysis tools analyze the data before processing is complete. This includes looking for patterns, analyzing the data in depth, and determining the meaning of the data.
There are scores of tools available in the market today, including Apache Hadoop, which allows the distribution of processing across connected computers. It can even scale from single to multiple servers and is preferable for batch processing.
Apache Storm, on the other hand, is a free and open-source distributed computation system made for real-time processing.
But as big data moves to the cloud, so will processing. With its accompanying processing speed and effectiveness, the cloud allows enterprises to combine their tech platforms into a single adaptable system.
Plus, it offers seamless integration between systems, not to mention its cost-effectiveness.
All of which means the day is not far when you will find most enterprises conducting this exercise entirely in the cloud.
What is the Future of Data Processing?
Cloud computing is the future of data processing. As big data moves to the cloud, companies are benefiting greatly from this concept.
Cloud-based big data enables organizations to integrate their entire platforms into a single adaptable system.
These cloud platforms are not expensive and provide seamless opportunities to grow capabilities with the improvement in organization level.
Let’s see what changes data processing will bring in the future:
- Expansion of cloud migration
- Machine learning will enhance observations
- Huge demand for data scientists
- Privacy will remain a big concern
- Actionable and fast data will be the upcoming big data
These are the major predictions made for the future of data processing. Big data usually depends on Hadoop and NoSQL databases to inspect data in batches.
Actionable and fast data is related to processing in real-time streams. This shows businesses can make important decisions immediately and act instantly after receiving data.
As said, today’s world is full of options. If you are looking for an all-round system to help with your data processing, please check out Oyster, a customer data platform by Express Analytics.
Oyster is a modular customer intelligence system that can fetch data from not only multiple sources, but its AI-based algorithms can help your business understand who its best customers are.
Conclusion:
Data consist of various details associated with organizations, individual users, institutions, and researchers.
Both data scientists and data engineers are needed to help organizations understand the growing importance of information generated daily. Overall, data processing is an essential task that is tricky to execute as it is a repetitive process.
More and more data is being generated and processed every day across the globe. Hence, there is a need for data scientists and data processing for the functioning of society.
People and businesses rely on data to make intelligent decisions. In the future, perfect analysis will be a mandatory skill for businesses to stay competitive and make powerful decisions.
Build sentiment analysis models with Oyster
Whatever be your business, you can leverage Express Analytics’ customer data platform Oyster to analyze your customer feedback. To know how to take that first step in the process, press on the tab below.
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.