The global data cleansing tools market is all set to see a meteoric rise in the coming years following a rise in the digitization of global business in the ongoing COVID-19 pandemic.
Also, the universal data cleaning tools market is fragmented, with the existence of various manufacturers in both developing and developed areas. Learn more about the growing importance of Data Cleaning (data cleansing) in analytics.
Data cleansing tools are needed to remove the duplicate, inaccurate data from databases.
The pandemic has become a catalyst for the rising need for data cleansing tools.
Since businesses globally are now forced to move online, be it telecom, retail, banking, or even government departments for that matter, the requirement for such tools is being felt even more.
Table of Contents
- What Is Data Cleaning?
- How Do You Clean Data?
- 5 Steps in Data Cleaning
- Why Is Data Cleaning Required and its Benefits
- What Is The Importance Of Data Cleaning In Analytics?
What is Data Cleaning?
The data cleaning process can include statistical methods of deleting incorrect, wrongly formatted, and incomplete data within a dataset.
Such data leads to false conclusions, making even the most sophisticated algorithm fail. Data cleansing tools use sophisticated frameworks to maintain reliable enterprise data.
Solutions for data quality, include master data management, data deduplication, customer contact data verification and correction, geocoding, data integration, and data management.
Our experts are on standby if you want to know more about data collection and cleaning. Fill this short form to get in touch.
One more outcome of a data cleaning process is the standardization of enterprise data.
When done correctly, it results in information that can be acted upon without any more course correction to another data system or person.
For all of this, your enterprise needs to have a data quality cleaning strategy that has to align with the business goals.
How Do You Clean Data?
Like any such process, cleaning data requires technique and as well as accompanying tools.
The data cleaning techniques may vary since it is related to the types of data your enterprise, and so the tools to deploy them.
Here are the first steps to tackle poor data:
Inspect, clean, and verify. The first step is to inspect the incoming data to detect inconsistent data.
This is followed by data cleaning, which is to remove the anomalies, followed by inspecting the results to verify correctness.
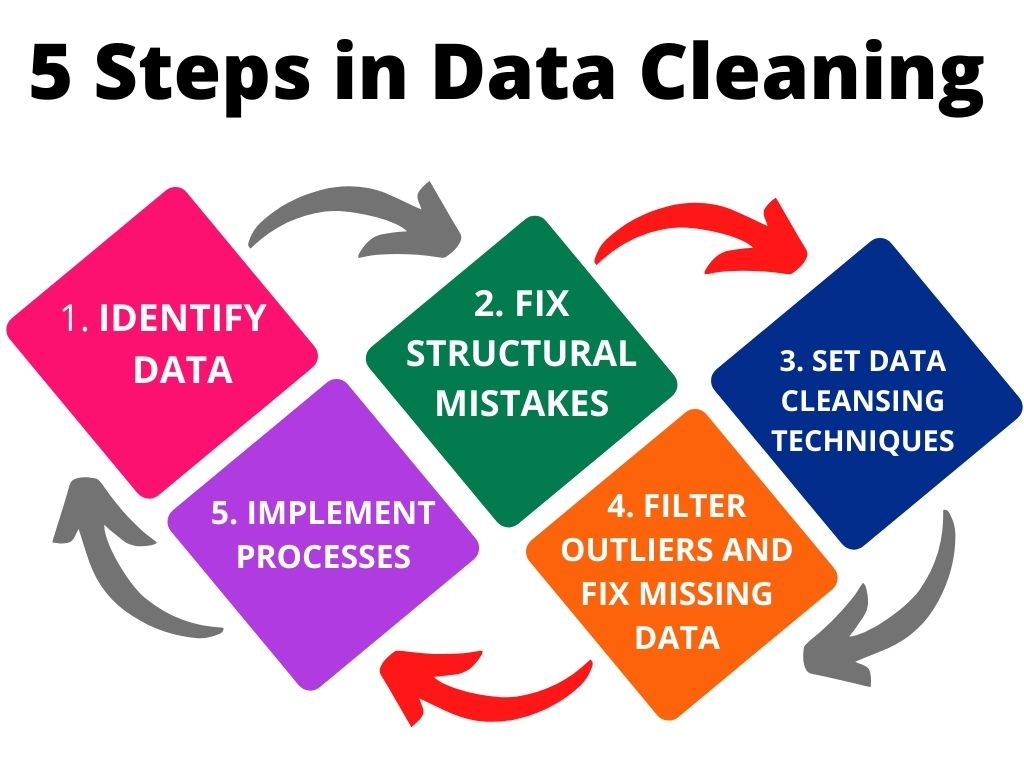
5 Steps in Data Cleaning
When integrating several data sources, data can be mislabeled or duplicated. When data is inaccurate, results and algorithms are unpredictable, even though they may appear correct.
There is no perfect method to describe the accurate steps in the process of removing irrelevant data or correcting errors because the process is not the same for all datasets.
However, it is very important to come up with a template for the data cleansing process to ensure you are not making a single mistake every time.
The basic step is to identify data that needs to be cleaned and remove duplicate observations.
Use your data cleaning strategy to identify the data sets that have to be cleaned. This is the primary responsibility of data stewards, individuals tasked with maintaining the flow and the quality of data.
Among the first steps here are to start deleting unwanted, irrelevant, and duplicate observations from your datasets.
The reason why deduplication is first on the list is that duplicate observations occur most during data collection.
It’s like nipping the problem in the bud. Duplicate data also flows in when you combine datasets from multiple places, received perhaps from multiple channels.
Unwanted observations are those datasets that may be correct but do not conform with the specific problem you are trying to analyze.
So if you are looking for patterns of young girls spending online, any data that includes teenage boys is irrelevant.
Fix structural mistakes
Errors in the data structure are weird naming conventions, typos, and some such inconsistencies. These can lead to mislabeled categories or classes.
Set data cleansing techniques
Which data cleansing techniques (data cleaning techniques) does your enterprise want to deploy?
For this, you need to discuss with various teams and come up with enterprise-wide rules that will help transform incoming data into a clean state.
This planning includes steps like what part of the process to automate, and not.
Filter outliers and fix missing data
Outliers are one-off observations that do not seem to fit within the data that’s being analyzed. Improper entry of data could be one reason for it.
While doing so, however, do remember that just because an outlier exists, doesn’t mean it is not true.
Outliers may or may not be false but they may prove to be irrelevant you’re your analysis so consider removing them.
Missing data is another aspect you need to factor in. You may either drop the observations that have missing values, or you may input the missing value based on other observations.
Dropping a value may end up in losing information while adding a presumptive input means risking losing data integrity so be careful with both tactics.
Implement processes
Once the above is settled, you need to move to the next step, which is the actual implementation of the new data cleansing process.
The questions here that need to be asked and answered are:
a. Does your data make complete sense now?
b. Does the data follow the relevant rules for its category or class?
c. Does it prove/disprove your working theory?
Eventually, you need to be confident about your testing methodology and processes, which will be evident in the results.
If adjustments have to be made in the procedure, they have to be done and then the entire process has to be “fixed” in place.
Periodic re-evaluation of the data cleansing processes and techniques must be made by your data stewards or data governance team, especially when you add new data systems or even acquire new business.
Call it data cleaning, data munging, or data wrangling, the aim is to transform data from a raw format to a format that is consistent with your database and use case.
Use Cases of Data Cleaning
Our senior data scientist Vinay Dabhade explains the many use cases of data cleaning at length.
1. ETL developers typically face issues with addressing standardization. For example, the state of California might show up as ‘CA’, ‘California,’ California state’.
2. Dates and timestamps require a lot of cleaning and transformation as multiple systems with multiple regions can mess up a company’s data warehouse.
For example, if you are extracting data from an ERP and storing it in AWS Redshift DW, you most likely will have to deal with date and timestamp formats.
3. Case-sensitive data, lead and lag spaces in fields, and invalid or bad UTF-8 characters are typical use cases an ETL team looks for when doing data cleaning.
4. Data science teams and analysts also spend a considerable amount of time cleaning data for their use cases.
5. Data scientists have to deal with missing or incomplete data. To prepare the dataset typically the records are filtered out or data is imputed to get a clean dataset with minimal noise or outliers.
For example, you are building a product inventory demand prediction model and considering the last 2 years’ historical data, but the inventory system was changed last year, and you are getting different fields or values than the previous system.
Here, the data scientist has to do data wrangling to create a clean and uniform dataset to build a robust predictive model.
Another example I have observed is when calculating lifetime values of customers you come across customers who have given 10-15 times more revenue than your average customers.
In this case, the data science team has to analyze whether this is an outlier and whether will it impact the analysis. If found to be an outlier it has to be removed to maintain the quality of data.
Why is Data Cleaning Required in the First Place? What are the Benefits?
Data cleaning importance and benefits: The answer in short would be to obtain a template for handling your enterprise’s data.
Not many get this: data cleaning is an extremely important step in the chain of data analytics. Because its importance is not understood, it is often neglected.
The result: erroneous analysis of your data, which translates into a waste of time and money, and other resources.
Having clean data can help in performing the analysis faster, saving precious time.
Why data cleaning is required is because all incoming data is prone to duplication, mislabeling, missing value, and so on.
The oft-quoted line: Garbage in means garbage out explains the importance of data cleansing very succinctly.
Obviously, if input data is unreliable, the output, too, will be so.
Benefits of data cleaning include:
Deletion of errors in the database
Better reporting to understand where the errors are emanating from
The eventual increase in productivity because of the supply of high-quality data in your decision-making
Grow your business operations using our data cleaning services
Tools for Data Cleaning
No two data cleaning processes are the same; it differs from enterprise to enterprise, depending on the business goals.
Data cleaning techniques come with their own set of data cleaning tools, some manual, some automated.
These tools are used to manage, analyze, and scrub data from various channels like emails, social media, website traffic, and so on.
Data cleansing tools remove problems like formatting errors. They are used to support IT teams managing data, sometimes helping transform the data from one format to another.
Software like Tableau Prep, Tibco Clarity, Informatica, and Oracle provide visual and direct ways to combine and clean your data.
Using such data scrubbing tools can save data analysts a considerable amount of time and also give them more confidence about their data.
Tibco Clarity, for example, is an interactive data cleansing platform that uses a visual interface to streamline data quality improvements.
It also allows for deduplication operations and checks of addresses before moving the data down the line.
Informatica Cloud Data Quality tool: Informatica Cloud Data Quality tool works on a self-service model.
It also is a tool for automation, wherein almost anyone within your business can be empowered to fetch the high-quality data they need.
This tool allows you to leverage templated data quality rules for standardization. It helps with data discovery, and data transformation, among others, and even has artificial intelligence automating the process.
The Oracle Enterprise Data Quality tool: The Oracle Enterprise Data Quality tool is a slightly advanced one in the market but is one of the most comprehensive data management tools out there.
Its features include address verification, standardization, and profiling.
Data cleaning tools can be used to remove irrelevant data (values), delete duplicate values, avoid typos and similar mistakes, and take care of missing values.
All meaningless or useless data has to be removed from your database. Duplicates, on the other hand, increase the amount of data and also need to be deleted.
Typos are a result of human error and also need to be fixed. You need to take care of spellings and upper/lower case in your data entries.
After all, what is most important is that data types must be uniform across your dataset. This means numeric values must be numeric and not boolean.
Data quality tools also take care of missing values.
What is the Importance of Data Cleaning in Analytics?
What is the importance of data cleaning in analytics? Data cleansing is the first crucial step for any business that wants to gain insights using data analytics.
Clean data allows data analyst scientists to get crucial insights before developing a new product or service.
Grow your business operations using our data cleaning services
Cleaning of data helps an enterprise deal with data entry mistakes by employees and systems that do so occasionally.
It helps adapt to market changes by making your information fit changing customer demands. What’s more, data cleaning helps your enterprise migrate to newer systems and in merging two or more data streams.
In conclusion: There’s little doubt that data cleaning is an extremely vital step for any business that is data-centric. It helps businesses stay agile by helping them adapt to changing business scenarios.
A successful data cleaning strategy means your data cleaning choices must align with your data management plans. When all of this is done, data cleaning helps improve data quality within your enterprise data management system.
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.