
In the first post on this topic, we defined customer lifetime value (CLV) and learned about customer lifetime value models. How to use machine learning in predictive CLV models (Customer Lifetime Value Prediction Model).
In this post, we’ll learn how machine learning can be deployed to predict CLV. Customer Lifetime Value CLV is a customer’s past value plus their predicted future value. Predictive CLV is to calculate how much value a user will bring to the business in the future.
Machine learning (ML), a subset of AI, combines algorithms and statistics to do a specific job without human supervision. It does so by finding patterns inside the big data sets. ML is a huge asset today while predicting CLV (Customer Lifetime Value).
Predictive CLV (Customer Lifetime Value) aims to model the purchasing conduct of buyers to infer what their actions in the future will be.
For this, ML models are a suitable alternative to probabilistic models because they can use more features. Probabilistic models are a class of models where parameters are fitted to the data by training the model with theoretical gradient descent.
So, when you’re predicting future CLV, you are tackling two distinct problems:
- You need to forecast the future value of existing customers with previous transaction records
- You also need to predict the future value of new customers
Knowing about your customers inside out is very important in today’s customer centric market. Speak to Our Experts to get a lowdown on how customer lifetime value model help you.
So, how do you solve both of these problems? Several modeling techniques can be deployed. One way is to build predictive CLV models in Python or R. You can also use deep neural network models for the same.
Steps in building an ML model for predicting customer Lifetime Value Model:
Building an ML model to predict your customer’s lifetime value features certain key steps:
- Collect & clean customer data: First, you need to have clean data for each customer. You must have a customer ID that’s used to differentiate individual customers and a purchase amount for each purchase that customer has made.No matter which model you use, you must perform a set of preparation and cleaning steps that are common to all models.
- Build a model: Next, you will need to implement ML algorithms to search your dataset for patterns. Once you have a list of patterns, you can design steps to analyze and understand those patterns: To prepare for training the models, you must choose a threshold date.
- Check if the model is successful: After all the previous steps, it is extremely important to evaluate that the model is working correctly.
Our data analyst Mehar Singh Gambhir shows you how to build an ML model for predicting CLV.
Steps in building an ML model for predicting CLV
The following steps are involved in the building of a machine learning model to predict customer lifetime value (CLV):
1. Clean And Prepare Data:
- The first step is to prepare the data set and select the variables to be used as features for the training of the model. Before performing any processing or analysis on the data, some basic data cleaning operations need to be performed on the data set. These include:
- not using columns with low variance
- filling or eliminating rows containing null values
- getting rid of duplicate records to avoid redundancy
- For the purposes of this model, we are using a sample data set consisting of standard transactional data of a company, where each row corresponds to a purchase made by a customer. The data set consists of fields like the unique customer ID, date of transaction, quantity of products and total price of the purchase.
- Here is a sample of the initial raw data set we will be starting our CLTV model building with:
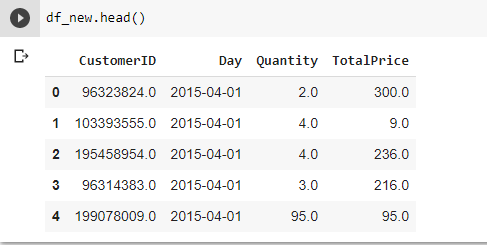
- These are raw features for a basic model, but one can incorporate additional features like browsing data that may include- browsing time, addition to carts, product searches. Also, email response data from marketing campaigns or promotions can be added to the set of features. Some metadata about the customer can sometimes be useful for predicting the lifetime value as well.
- We split the data into training and test sets using a threshold date (here taken as 2019-08-09). A training period of 1681 days is considered between 2015-01-01 and 2019-08-09. The test period will be the next one year till 2020-08-09, which is the time period for which we will predict the lifetime value of a customer.
- We just have 2 variables right not corresponding to each transaction, which won’t be enough for predicting customer lifetime value. So, we apply some feature engineering on the raw data to evaluate some insightful features for this purpose.
- First, we group the rows on customer ID and transaction day and aggregate using sum() to evaluate the transactions made by each customer daily.
- Now, for each customer ID we calculate the following values:
- Recency: The active duration during which a customer made purchases in that time period
- Monetary_value: Total amount of all purchases made by the customer in the given time period
- Frequency: Number of purchases made by a customer
- T: The number of days between the first transaction date of a customer and the last day of the training period (in this case 2019-08-09).
- time_between: The average number of days between successive transactions of a customer
- avg_basket_value: The average cost of purchases made by the customer
- avg_basket_size: The average quantity of products purchased
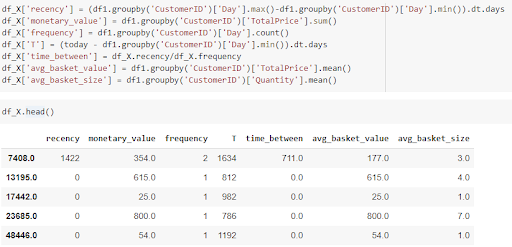
- Target_monetary: This is the target variable which is calculated as the monetary value of the customer calculated in the test period of 1 year.
- This is how the final data set looks like:
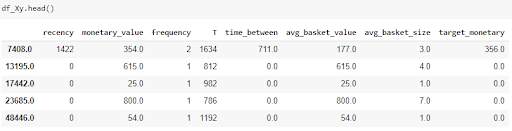
2. Pre-processing:
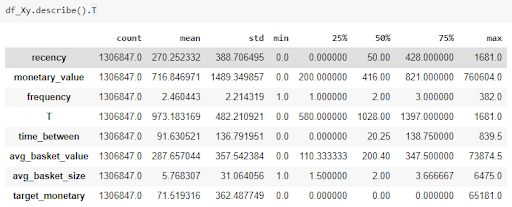
As we can see from the description above of the input variables, the difference in the min and max values is considerably high.
The values under some variables like monetary_value, average_basket_value are quite skewed which would affect the model training process. We have applied some pre-processing on the data to normalize.
We initially apply a log function on some columns with high range values like monetary_value, time_between, avg_basket_value & avg_basket_size to bring down the values.
Then subtracted all the row values by their mean and divided by the standard deviation, for normalizing the data for all the columns.
The normalization of data reduces the range of values for the model to train thus speeding up the training process and optimizing its performance.
3. The Two-Stage Pipeline Approach:
Most CLTV models use the conventional approach of predicting the CLTV value for a customer using the RFM variables.
But there is a possibility that a customer might have churned (stopped doing business with the company) within the training period and despite that, a finite CLTV could be forecasted for that customer in the test period.
A drawback of this approach is that it won’t be able to take customer churn into consideration before training. Hence, in this model, we are going to follow a 2 stage pipeline approach which includes:
1. Classification model for predicting customer churn:
The customers who have a monetary value <=0 in the test period are supposed to be the customers that churned in the training period.
So we label the customers that churned as False and the other as “True”. We train a classification model on 80% of the data as a training set using deep learning with the features described above for predicting whether the customer churned in that time period or not.

We trained a classification model with ~83% accuracy and auc of 0.737.
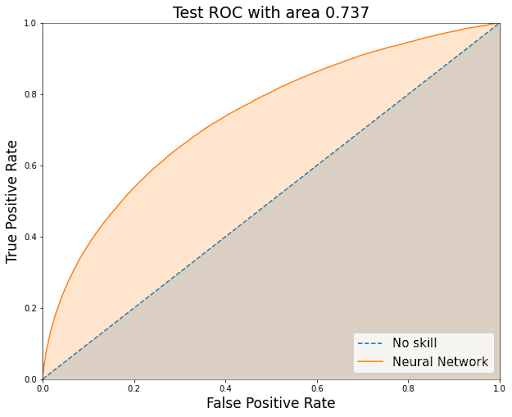
2. Regression model for forecasting lifetime value:
We train a regression model using deep learning on the customers who did not churn from the training set to predict the lifetime values for next year.
Using this model, we predict target_monetary value for customers in the test set. The following parameters were used for training the regression model.
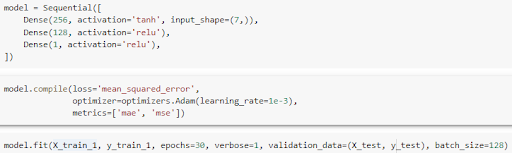
We then combine the two model outputs using probability from the classification model and the monetary value obtained from the regression model.
The final_amt is calculated as the product of predicted probability and target_monetary value which will be considered as the lifetime value of that customer for next year.
The mean absolute error of this model is calculated at about $103. We also calculated the overall lifetime values across all customers as:

Some things to bear in mind before building an ML model:
You will need to define the time frame for calculating the CLV. It can differ from industry to industry.
- Identify what type of machine learning problem
- Create training and test datasets. You will use the training set to build the model.
In conclusion: Once your ML model is a success, you can use the results to identify the category of customers more likely to spend money than the others, & make them respond to your offers and discounts with a greater frequency. These customers, with higher loyalty, are your main marketing target. This means retailers can effectively run campaigns based on the predictive lifetime value of any given customer.
References:
Predicting Customer Lifetime Value with AI Platform: training the models
Customer Lifetime Value Prediction
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform