
Recommender System: A Primer
What is a recommender system? A recommender system is a compelling information filtering system running on machine learning (ML) algorithms that can predict a customer’s ratings or preferences for a product.
A recommendation engine helps to address the challenge of information overload in the e-commerce space. What is Recommender System? How to build a Recommender System a Primer.
Modern recommender systems were created first by e-commerce giants like Amazon and then popularized by OTT platforms like Netflix.
But now you might encounter recommendations in almost every space of the digital world, be it Facebook Posts, Insta Stories, YouTube videos to food delivery services, and e-commerce business.
With the introduction of cost-effective and easily available software, more and more enterprises can now develop and deploy their recommender systems.
Building A Recommender System
Building recommendation engines: One software that Express Analytics uses in developing recommenders engine for clients is the Neo4j software. This is a graph database management system, unlike traditional RDBMS.
The Neo4j foundation is on “Nodes”, “Relationship”, and “Properties”. A “Node” is a data or record in a graph database while a “Relationship” is an element using which two nodes of a graph can be connected.
This relationship creates a pattern that associates two chunks of information together and defines a flow by assigning a direction to it. We can add pieces of information to our nodes and relationships by assigning properties to them. But more on the Neo4j later.
Just to make it easy to understand it better, for this blog post, we will help explain how we design a recommendation engine for an e-commerce client.
Increase Your ROI with Intelligent Product Recommendations
But before we dive deep into building a recommendation engine let’s add context to the analogy of using one with this example. Let’s say there are 27,000 restaurants in New York City.
One evening, you plan to dine out. Being new to the city you do not know which restaurant to choose.
Clearly, the selection depends on a lot of “factors” such as the distance from your location, your food preference; maybe even your country of birth. These factors are in a way “certain or fixed” and can be translated into numbers.
But there are some “uncertain” factors too, to be taken into account like your mood or your curiosity to try something you haven’t before. Does that mean for an analyst it is impossible to predict what kind of cuisine you want to try out tonight?
It is rational for an analytics model to have uncertainty in the mix as several factors are involved to derive the results.
But those uncertainties can be removed by building more algorithms or putting more context to the filtering, or generating more recommendations per algorithm to increase diversity.
The whole idea is to use the customer’s preferences which are reflected by his browsing pattern and generate recommendations around it.
3 Types of Recommender Systems
Before going ahead with the explainer on how to build a recommendation engine, let us learn some of the various types:
Recommendation systems can be classified into three categories:
- Content-based filtering
- Collaborative Filtering
- Hybrid
Below flow chart can make the classification and sub-classifications of recommender systems a bit clearer:
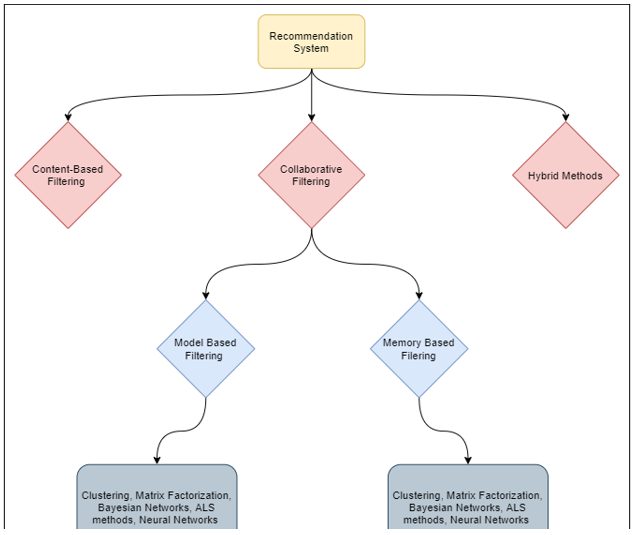
Recommendations can be made based on the customer’s recent purchase history, demographics, and gender.
What is Content based Recommendation System?
Recommendations through content-based filtering techniques are influenced by what the user has browsed earlier, or what he is currently browsing.
It is mostly dependent on keyword searching techniques and tries to follow the user’s own browsing patterns by filtering items based on keywords to describe the items and make recommendations around them.
What is Collaborative Filtering Recommender Systems?
Unlike content-based filtering which only takes into account user-specific item interactions, the collaborative filtering technique follows a more mature approach and finds out similar users based on user-item interactions.
An example: consider two user browsing patterns. We can increase the confidence level of the two users being similar by comparing the number of common products they have browsed.
What is Hybrid Recommendation System?
Once you mix concepts of content-based filtering and collaborative filtering to generate recommendations you have developed a hybrid system.
So, let’s commence building a recommendation engine for a hypothetical e-commerce firm.
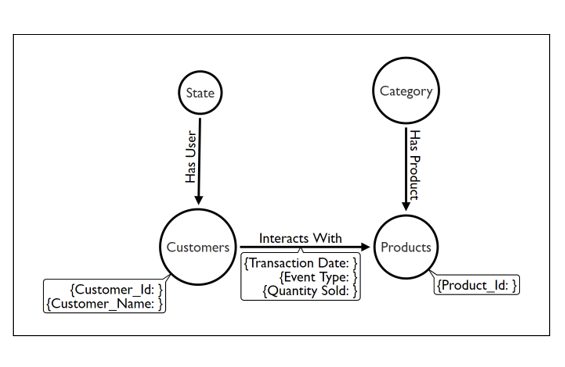
Consider the above graph data structure. Here, we have four nodes, i.e. State, Customers, Category, and Products, and three relationships with directions connecting the four nodes. Their respective properties are in the assigned dialogue type box.
We want to recommend products to the customers although we can recommend them anything, making rich recommendations will increase the probability of them buying one. For this purpose, we will develop some algorithms to make the recommendations.
Consider the following Node-Relationship structure of the database. We have data for customers stored in ‘Customer’ nodes with properties “Customer_Id” and “Customer_Name”. Separately, we have information on all the distinct products under the “Product” nodes and their respective categories under the “Category” node.
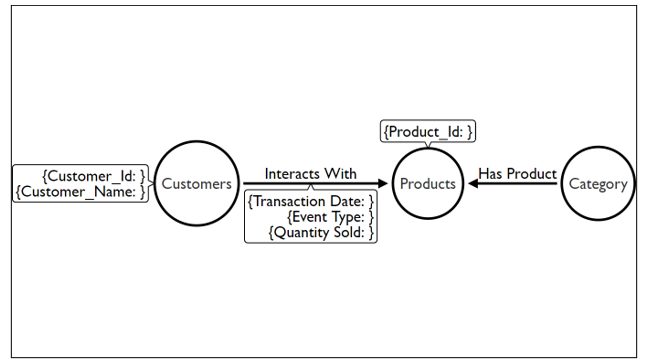
Each customer individually interacts with a set of products and this interaction is captured in the ‘Interacts With’ type relationship. The relationship captures data on the date of interaction, the type of interaction i.e. ‘Purchase”, “Product View”, ‘Cart Addition”, ‘Wishlist” “Review” and the “Quantity” sold, if any.
Data alone does not drive your business. Decisions do. Speak to Our Experts to get a lowdown on how a recommender system can help your business.
So, can we come up with a recommendation system based on this information only?
Let’s say for each customer that has interacted with at least one distinct product we identify the categories of those products. To identify the most recent categories we arrange the categories in descending order of the transaction date and say consider at most the top 5 categories from that if present.
Till now, we have at best 5 recent categories for each customer who has interacted with at least one product. For each category in consideration, let us collect 5 products from each to have at most 25 products for recommendation to the customers. Simple, isn’t it?
Increase Your ROI with Intelligent Product Recommendations
Making Recommendations More Dynamic
Now let us make some more adjustments to the query to make our recommendations more dynamic.
Recommending a set of products from a category won’t spice the recommendation for obvious reasons so rather than recommending fixed products from each category we can recommend random products from the category each time.
Still not quite good, is it? Okay, what if we find the most popular products from each category based on the number of interactions and recommend them as an add-on, we can find the state of the customer too and find the most popular products in the same region. Hmm… now this looks good.
The recommendation of the above type comes under the “Content-based filtering technique” where we have used filtering on the customer’s browsing pattern to find the recommendations.
As a note, filtering is the key to generating rich recommendations. Start with a basic idea and build around it by including filters to generate recommendations the customer is most likely to buy.
Recommendation based on the Product A Customer is Searching for in Real-Time
Another content-based recommendation algorithm that we can develop is based on finding out products similar to the one being browsed at the moment.
Suppose one of our customers is browsing X product. That product belongs to a category as is mentioned in our database structure. To start, we can note the category and grab random products from that category to make our recommendations.
To make the recommendations more rich and relatable let us dig a little further. Like in the earlier example, filtering is the key here too.
As an example, look at the details we have about the browsed product. We know its category and its price.
To add more details to the recommendations, instead of grabbing random products we can grab products that belong in a certain price range. The price range can be around the price of the browsed product.
At last. We have our recommendations for products that belong to the same category and have a price around the price of the browsed product.
User-user Collaborative Filter-based Recommendations
The earlier two recommendations are running on content-based filtering which makes use of inputs from customers and builds recommendations around it. Now, let us build a collaborative filtering-based recommendation system.
Here the idea is to use the customer’s profile and make recommendations purely based on his/her preference and liking.
User-user collaborative filtering aims at finding customers who are similar to you based on the products you both are browsing, or by comparing the ratings you both give to a particular product.
Both the approaches are valid and adopt a different similarity measure to find similar customers.
This is where the Neo4j software proves to be superior to others as it provides some different similarity algorithms. To name a few — “Jaccard Similarity” and “Cosine Similarity” are mostly used in this type of collaborative filtering.
Suppose we have the data of ratings that each customer has given to a product. For this particular case let’s use the cosine similarity to calculate the similarity score whose value range between -1 and 1, where -1 is perfectly dissimilar and 1 is perfectly similar.
To compare the ratings firstly we need to have common products that the two customers have browsed. Let’s make two separate lists of the ratings for the common products in order by each customer. Let us call the two lists A and B. The cosine similarity is defined as:
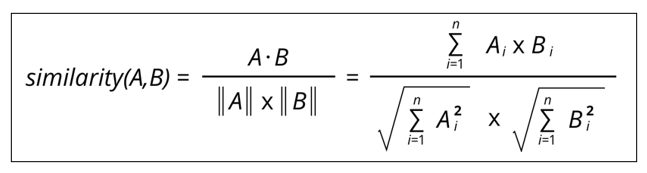
In our case, A and B are the lists of ratings of the common products browsed by the two customers. Imagine doing this for all the customer pairs in your database which have customer count in thousands. This makes the similarity-based algorithms computationally costly.
Suppose we have generated the similarity scores for each customer pair. The question is: how can we exploit this information and make use of it to generate recommendations?
Things are pretty logical from here onwards. Say you want to generate recommendations for a customer. Just grab the topmost similar customers based on the similarity score.
Now, make use of the logic we developed earlier during the content-based filtering examples. To start, we can recommend products that similar customers have purchased recently.
Or to add more context we can grab products only from the category of interest. We can even exploit the data if we have similar customers from the same state and can recommend the products that the customers from the same state have purchased.
In short, we can make use of any content-based filtering technique to generate recommendations once we have the data of similar users. With this, in a way, we are reducing the sample space to find our recommendations.
Earlier, we were looking at the whole database but here we are only considering customers who are most similar to other customers under consideration.
Let’s take a breather here. In the 2nd part of this post, we will show you how to use the Neo4j platform for building a recommender system, a comparison between the Neo4j, the MongoDB, and MySQL, and various use cases of recommendation engines.
Post Written By: Shubham Patidar, Devendra Lohar, Niraj Harwate, Pankaj Katkar and Vinay Dabhade.
References:
- When Connected Data Matters Most
- System Properties Comparison MongoDB vs. Neo4j vs. Redis
- How many nodes are required to set up a distributed system in order to test CAP theorem?
- Redis Enterprise: the high-performance caching solution
- MongoDB Use Cases
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.