
Part 1 of this post looked at the definition of Big Data and its importance in data analytics. In this post, we will tell you how to go about implementing your Big Data project, and the pitfalls to avoid while doing so.
Be it established or new enterprises, all of them need arrays that can sustain not just standard business intelligence (BI) but also support advanced analytics and applications that use artificial intelligence (AI).
We had said this in part one – to start, an enterprise and its key decision-makers must have a complete understanding of how a Big Data project differs from a traditional BI project (we’ve tried to explain what Big Data is in part one.), so will not spend time reiterating that.
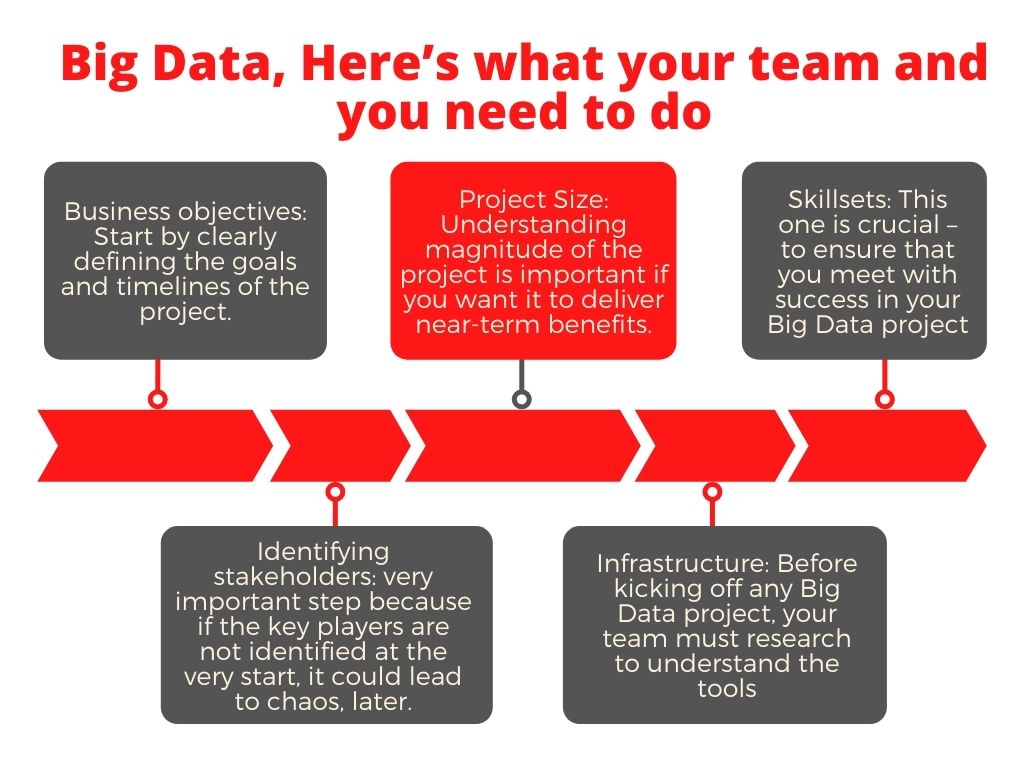
Before you set up your Big Data project, here’s what your team and you need to do:
Business objectives: Start by clearly defining the goals and timelines of the project. The stakeholders must agree on a common minimum set of objectives that will impact business. When we say stakeholders, they include the tech and design teams – these are crucial in the implementation of the project.
Project size: Understanding the magnitude of the project is important if you want it to deliver near-term business benefits. Big Data projects can get pretty complicated, so it is necessary to segment each of them into broader categories and create a plan around each.
Identifying stakeholders: This, too, is a very important step because if the key players are not identified at the very start, and the assignments are not aligned with them, it could lead to chaos, later.
Skillsets: This one is crucial – to ensure that you meet with success in your Big Data project, not only must those involved have the right skillsets like analytics skills, etc, but all of them, whether they be business, design, or tech-side, must have a common knowledge of the core big data skills and best practices. This means they should have a “working knowledge” of data management, integration, modeling, the tools involved, dashboards, etc. Only then can all of them be on the same page. Another mistake often made – skills sets for handling traditional data sets projects are not the same as those required for a Big Data project.
Infrastructure: This one is a no-brainer, in a sense. Before kicking off any Big Data project, your team must research to understand the tools – hardware and software – required for the project to be undertaken. IT has to work in consonance. Specifically, you need to decide the data management technology – from data storage to processing – which is most suited for your project.
Once you’ve kind of got your act together, you are ready to launch your Big Data project. You may have figured it out by now: there are three main reasons why such a project can fail: (a) poor project definition (b) poor scoping (c) not selecting the right personnel.
Now, here are some of the common pitfalls to avoid as you go about implementing it:
- Lack of appropriately scoped objectives
- Lack of required skills
- The size of Big Data
- The quality of Big Data
- The structure of Big Data
- Data management/integration
- Rights management
- ETL
- Data discovery (how to find high-quality data from the web?)
- Data veracity (how can we cope with uncertainty, imprecision, missing details?)
- Data verification
- Measuring the wrong thing
In conclusion, if done right, Big Data projects may be materialized in either: revenue gains, cost reductions, or risk mitigation, or something even more.
References:
10 Pitfalls Companies Should Avoid Before Implementing Big Data Projects
Six Keys to Maximizing Big Data Benefits and Project Success
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.